经过一个多月的打磨,终于到了数据透视表课程的收尾工作。有需要学习的小伙伴可以点击链接学习,前几章和中间的章节部分可以免费试看,如果觉得对自己有帮助或启发,也请购买支持,一经购买,永久观看学习,内容若有更新,也不会再收取任何费用,课程中的所有案例,都可以直接下载进行练习,加深印象。
今天给小伙伴来讲解一下数据透视表除了简单的拖拉字段之外,还有哪几种提升技能的玩法,简单易学,一看就会。
拿人力资源的考勤举例。先看一个简单的数据如下:
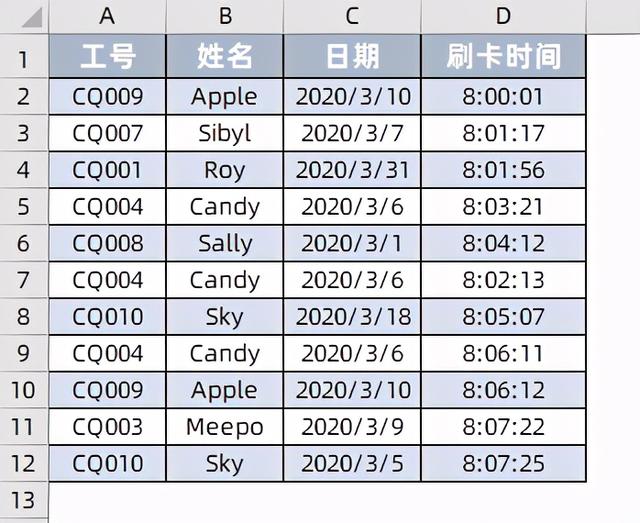
这是从某公司的考勤机上获取的员工打卡记录,从中可以看出部分员工不知道怎么回事不同时间之内连续打了好几次卡,但是这些其实都是无效的,我们要从上面获取的最终信息希望可以总结成下面这样。

下面就来看看这种效果是如何通过数据透视表来归纳和整理的吧。
首先将光标置于考勤表的任意单元格中,点击数据工具栏下的现有连接:

点击之后弹出现有连接对话框,点击下方的浏览更多:

弹出的对话框中找到我们正在使用的这个考勤表:
选中之后,直接点击打开:

保持默认的选中和下方的勾选,点击确定。弹出的导入数据对话框中选择数据透视表,数据的放置位置选择新工作表,点击下方的属性按钮:

弹出的连接属性对话框中,打开定义选项卡,接下来的关键操作和一系列的理解就从这个命令文本开始:

先删除文本框中的默认字样,直接输入:

文本内容:
select a.工号,a.姓名,a.日期,a.刷卡时间,count(b.刷卡时间) as 打卡次序 from [数据源$]a inner join [数据源$]b on a.工号=b.工号 and a.日期=b.日期 and a.刷卡时间>=b.刷卡时间 group by a.工号,a.姓名,a.日期,a.刷卡时间
完成之后确定,返回导入数据对话框后再次点击确定,生成空白的数据透视表,将相应字段拉入到行、列和值区域:
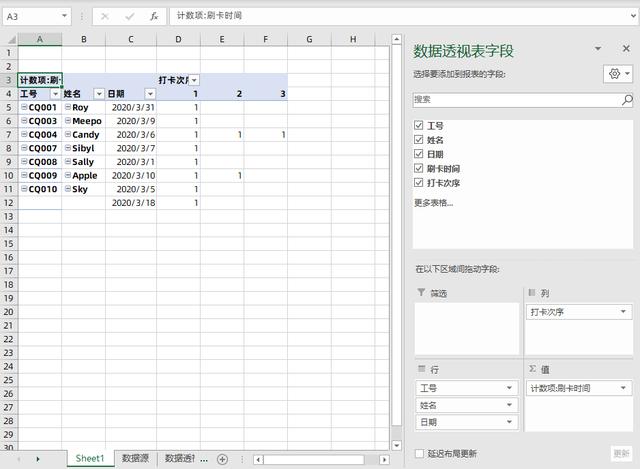
将值区域中的计算方式修改为求和,数字格式修改为时间格式,即可得到开头的效果:

下面来看看怎么理解命令文本中的SQL语句:
[数据源$]a,[数据源$]b这种写法的意思是说将数据源这种工作表变成两个同样的工作表,你可以想成是复制的同样的两份数据,我们用下图的方式来理解你就明白了:

a就是指上图中左边的数据表,b就是指右边的数据表。
a.工号,a.姓名,a.日期,a.刷卡时间:指的就是从a表中提取这些字段及相应的数据;
count(b.刷卡时间):count在函数中是计数的意思,这里同样也是计数,就是看b表中总共有多少份刷卡时间,哪怕是重复的都会参与到计数之中,空白的,没时间的就不参与其中了。
as 打卡次序:就是指将上面的计数命名为打卡次序,是取的一个名称的意思,不写这个也可以,系统会取个默认的英文名字。
from [数据源$]a inner join [数据源$]b:这个是联合查询的意思,在课程中对于这种left join, right join, inner join我已有过详细的解释,inner join提取的就是两个表中的共同信息,也就是我们说的取交集部分。
on a.工号=b.工号 and a.日期=b.日期 and a.刷卡时间>=b.刷卡时间:inner join/left join/right join进行联合的时候都要有条件,所以这个on后面跟着的就是根据哪些条件进行联合,取哪些满足条件的内容。如果是多个条件要同时满足,条件与条件之间就必须用and进行联合。a.工号=b.工号 and a.日期=b.日期,这个就是满足两个条件,取工号和日期相同的字段,第三个条件是a.刷卡时间>=b.刷卡时间,这个意思就是说用a表中的刷卡时间逐条与b表中的每一个时间进行比较,比如a表中的第一条是工号为CQ009、日期为2020/3/10及刷卡时间是8:00:01的数据与b表中的第一条进行对比,很明显这一条是满足三个条件的,所以计数为1;再将a表的这条数据继续与b表的第二条数据进行对比,很明显,这个工号、姓名都不匹配,所以不会提取出来,继续往下对比,发现后面的结果都不满足。
a表和b表的联合取交集最后生成的表格我们可以这么看,其实也就是结果了:

所以第一个打卡次序是1,再来用第二条记录Sibyl与b表中的记录进行对比,结果也只有一个,所以次序也是1,两个表中只有一条记录的,很明显结果都是1,所以就应该是:

但当比较到Candy的时候,情况就不一样了,第一次的时间是遇上了,条件都满足,结果是1,当比较到8:02:13的时候,条件同样满足,所以这个时候计数的结果就是2了,因此往下类推,结果就应该是:
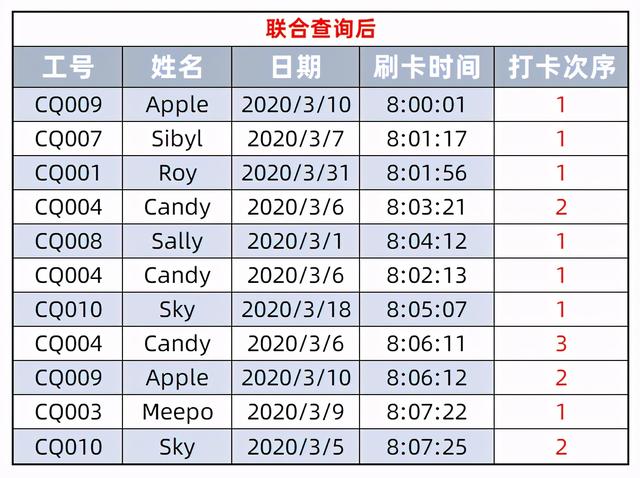
将这张表再进行数据透视表的布局排列,就得出了开头那样的效果。
是不是就非常容易理解了呢?
最后语句中的group by是分组的意思,相当于就是合并同类型,这个也跟SQL语句的语法有关了,课程中也会有相应的讲解。
下次内容我们再来看看下面这种效果该如何制作?
用SQL语句来实现分数的排名。(虽然用函数可以直接实现,毕竟这个是帮助我们来理解SQL语句该如何使用。)有兴趣的小伙伴可以先试着写一下,下期公布一下理解方式吧。

案例比较简单,就不提供文件下载了,你们可以直接自己手动输入一个进行练习吧。
观看不练假把式,更多关于数据透视表的内容和练习,记得点击下方的链接直达课程吧。
,