模拟场景需求:
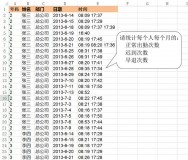
年末岁尾,单位考勤机故障,通过某种方法,有幸获得了考勤记录的原始文本数据,足足近30MB的大文档,用系统自带的文本文件,打开都很困难,打开之后,是一行行规律的数据,先截图如下:

文本数据属性

文本数据内容简介
半天拉到结尾,一共9万多行,突发奇想,能不能把他们逐行导入excel表格,分段插入每一列,也好做好分析,手动去粘贴,你要累死呀,还不如累死计算机呢^_^干再多的重复循环也是分分秒秒的事,用Python处理Excel文件的模块openpyxl,看我怎么样用它搞定我们的“文本大数据写入表格”。
1、用到的知识点:
python的循环读取,IO操作,file的读写方法,wb对象基本操作包括创建和保存,ws的操作遍历,cell单元格的读取和写入等。
2、用到的文件:
一个导出的考勤log日志数据,非隐私数据(已经脱敏处理,人名已经更改)如需要请下载,通过阿里云盘分享,链接如下:
http://www.aliyundrive.com/s/cjiSN9ZrGz7
3、操作步骤思维导图:

4、代码操作编写截图:
a、初级代码如下:
from openpyxl import Workbook
# 建立excel操作对象
wb = Workbook()
ws = wb.active
# 最python_man的文件读取方法,迭代遍历,不用担心读取文件过大问题
# 初级代码
with open('kaoqin.txt','r',encoding='utf-8') as f:
for line in f:
tmp = line.split() # 读取的行按空格分割
ws.append(tmp) # 按行写入excel表格
wb.save('result.xlsx')
成功了,虽然有点丑:

b、改进代码如下:
改进稍微难一点,用到了正则表达式模块和列表生成式,列表的切片合并等。
from openpyxl import Workbook
import re
# 建立excel操作对象
wb = Workbook()
ws = wb.active
title = ['date','time','id','name','workcode','status','authority','card_src','photo']
# 插入标题
ws.append(title)
#最python_man的读取方法
with open('kaoqin.txt','r',encoding='utf-8') as f:
for line in f:
tmp = re.split(r'[s="] ',line) # 分割字符通过空白和特殊符号="
ret = tmp[1:2] tmp[2::2] # 调节列表选项,选取需求的
ws.append(ret)
wb.save('result2.xlsx')

改进版代码
今天的例子要活学活用,关键练基础,熟悉python的openpyxl处理表格的思路,愿一路有你,好好学习,openpyxl操作有疑难请参阅<python办公自动化openpyxl处理excel(基础篇)>,python基础不好的,请参阅其它,或者关注作者即将退出的python基础内容哦。
,