原创: MOZA 合天智汇
01
前言
毕业设计给自己挖了个巨坑,虽然这个设想从我大二开始就已经有了一个大概的模型,但是实际实现起来与想象之中还是有很大的区别,特别是在漏洞报告准确度,与及速度方面有一些比较难的取舍,所以就开了一个新系列,记录一下自己玩死自己的过程。
02
关于Web漏洞扫描器
目前主流的漏洞扫描器大概分为以下三类。
主动型:直接主动发起扫描请求。(ps: 图自己画的,丑别怪我hhhh)

被动型:利用中间代理或者别的方式进行发现漏洞。

云扫描:部署在云端的扫描器,用户通过浏览器就可进行扫描。
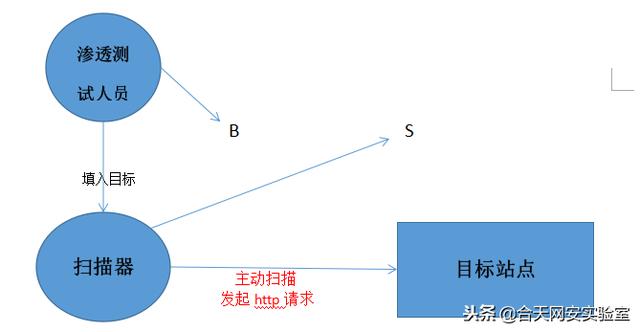
这里我打算做的是主动型与云端型,主体是主动型,主动型做好了,改成云端的不难。
03
扫描器的工作流程
首先作为一个自动化的测试工具,得先弄清楚扫描器与手工测试的区别
手工渗透测试的流程如下
- 信息收集
- 漏洞发现
- 验证漏洞
- 利用方法(EXP或者POC)
- 编写测试报告
扫描器的流程
- 信息收集
- 发现漏洞(漏洞验证)
- 生成报告
人为的渗透测试需要签写各类合约,在不破化业务的功能性下,尽可能的获得更多的数据与及权限。但是扫描器不一样。只需要点到即可,验证漏洞,不需要后续的漏洞利用环节。
https://shell01.top/2018/11/11/web-scan-01/ - 信息收集
其中信息收集不管是在人为的渗透测试,还是扫描器中都是至关重要的一步,没有信息收集,那就不会为下一步的发现漏洞做铺垫,越多的信息对整个渗透测试或者扫描过程来说都是愈好的。
在WEB扫描中,我们大概所需要的信息如下
IP信息:其中这里的ip包括端口开放信息,c段信息等等。
子域名: 企业一般会把各种业务放在二级域名下,比如说百度的网盘业务地址为:pan.baidu.com
指纹信息:知晓目标的指纹信息可以去找相应的nday实现攻击
敏感信息:敏感目录,备份文件,未授权访问的后台,邮箱,数据库等等
超链接: 在爬虫对目标站点进行爬取时,都应该进行入库处理,方便后续处理
https://shell01.top/2018/11/11/web-scan-01/ - 漏洞发现
在信息收集完毕之后,就需要对所收集到的内容进行漏洞发现,在漏洞发现之后还需要进行漏洞验证,避免出现大量误报,提高准确率
以下是主要进行的方式
端口:识别端口服务,进行相应的爆破,0day测试
URL:识别参数,进行类似sql注入等测试
cms:指纹识别。进行入库匹配相应poc
http协议 :改变各类参数,进行fuzz
报告阶段
生成html或者execl格式报告
04
如何设计
扫描器的设计我们得遵循一些原则,不然做出来的东西,难以维护,难以增减模块,那不是我们想要的。
1,足够的独立性。 如果模块之间相互影响太大,牵一发而动全身那明显不是我们所需要的。
2,单一职责原则 如果某一个模块担任了太多的功能,那么很可能某个挂了然后剩下的也会挂的,所以一个模块一个功能是非常必要的。
3,高并发的设计思想 扫描器如果做不到高并发,我想没人愿意等到漫长的扫描时间。 所以根据以上信息,我们可以确定一下我们漏洞扫描器的功能模块。
一 爬虫模块: 负责爬取目标站点可见的url,进行相应的入库处理,然后分级处理,比如说可以递交到敏感信息模块去匹配信息,又或者递交给漏洞检测模块进行检测。爬虫模块作为漏扫的主要眼睛,必须非常壮硕,所以在未来的实现爬虫模块篇中,将会是个问题。
二 域名探测模块: 进行子域名的查询,包括二级,三级,多级。这里实现的方式主要有爆破,dns,搜索引擎。
三 端口扫描模块: 通过各种方法获取真实ip 爆破服务器端口,将结果递交给指纹识别模块进行识别与爆破模块进行相应服务的爆破。
四 指纹识别模块: 内置大量指纹信息,居然可拓展的性质,进行相应的指纹识别,并将识别结果提交漏洞检测模块进行相应的nday查询。
五 敏感信息模块: 具有大量敏感信息目录,进行爆破操作,或者从爬虫获取相应数据进行匹配。
六 爆破模块: 内置各类服务爆破操作。
七 漏洞检测模块: 分为常规漏洞检测,与0day/nday检测,如何做到高效率的检测,又是一个问题了。
八 生成报告模块: 将结果输出成扫描报告。
九 “主控模块”:
进行各模块安全可控的调度,以高效率的运转。
05
END
如何实现,请期待接下来的文章,有好的设计方法或者思想的可以评论呀~ End